我鐵人賽寫的「敏捷實踐」,其實是 Harness Engineering

2025 年 8 月我寫了兩個 iThome 鐵人賽系列,加起來 60 篇,標題裡有「敏捷實踐」四個字。其中一篇拿了佛心分享佳作。
半年後回看,我寫的其實不是敏捷。是一個當時還沒命名、2026 年 2 月才被 Mitchell Hashimoto 和 OpenAI 幾乎同時叫出名字的東西:Harness Engineering。
這篇分四段:
- 先定義 Harness Engineering 是什麼(公式、命名源頭、三代演進、OS 類比)
- Fowler 的框架:Feedforward vs Feedback 兩類控制
- 八大技術模組與失敗博物館
- 鐵人賽 60 篇對照:我當時做對的、我當時完全沒碰到的
不是事後套詞。做完對照你就會看到,那 60 篇寫下的東西可以用 Harness 的語彙重新分類每一篇。但也有幾塊我當時根本沒意識到要做。兩邊都誠實講。
一、Harness Engineering 是什麼
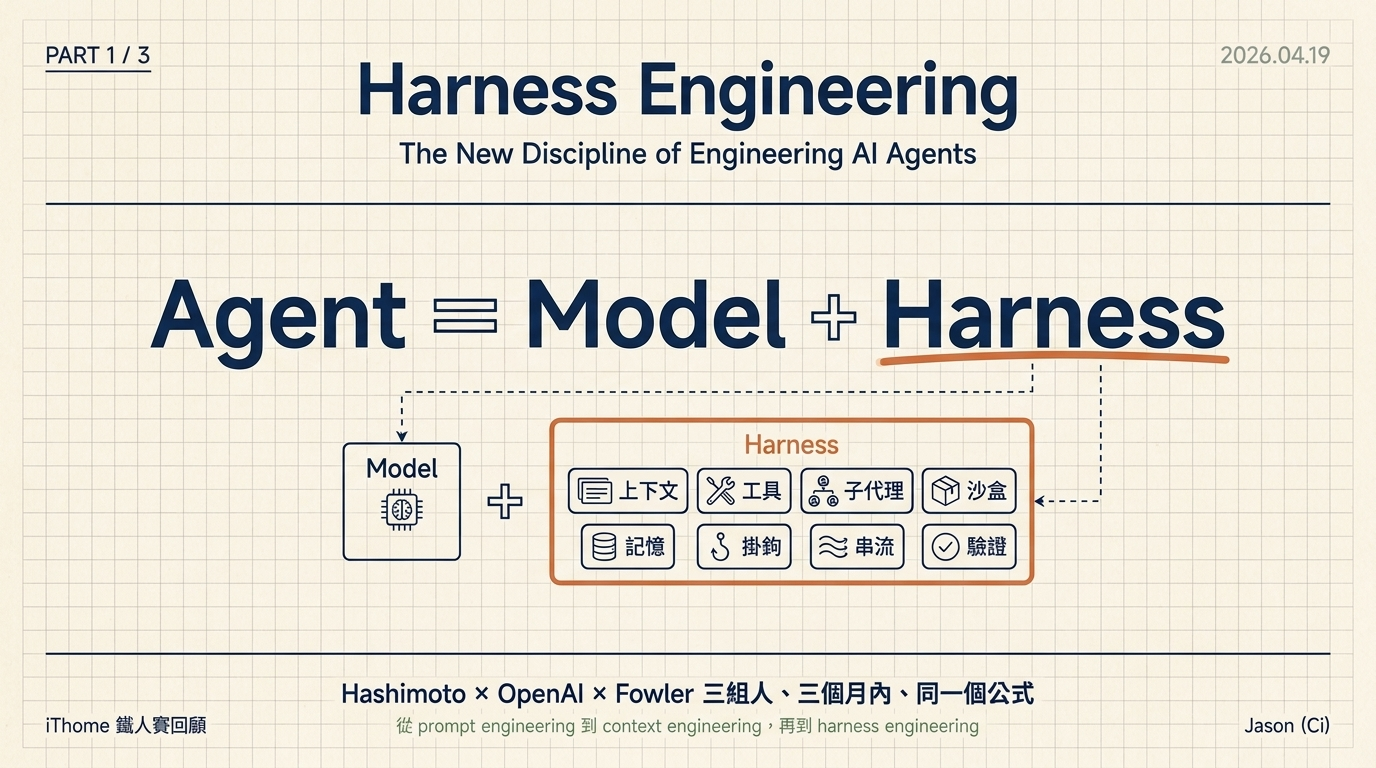
公式:Agent = Model + Harness
先給一句話定義。Mitchell Hashimoto(HashiCorp 創辦人、現在做 Ghostty)在 2026-02-05 的〈My AI Adoption Journey〉寫下這句話:
"Harness engineering is the idea that anytime you find an agent makes a mistake, you take the time to engineer a solution such that the agent never makes that mistake again."
翻成我自己的話:每次 agent 出錯,你不是去改 prompt,而是把修正工程化到它的執行環境裡,讓它以後不會再犯同一個錯。
兩週後,OpenAI 的 Ryan Lopopolo 在〈Harness engineering: leveraging Codex〉用同一個公式命名:Agent = Model + Harness。Model 是 LLM 本身,Harness 是模型以外的一切 —— 規格、測試、工具、權限、記憶、hook、eval,全部。
再兩個月,Thoughtworks 的 Martin Fowler 和 Birgitta Böckeler 在 2026-04-02 發了〈Harness engineering for coding agent users〉,把這個詞從 practitioner 筆記升格成一個有定義、有分類、有流程的學科。
三組人、三個月內、同一個公式。這個時間點的同步命名很罕見,代表社群對「這件事需要一個新名字」已經有共識。
三代演進
要理解為什麼是這個名字,把時間拉長一點看:
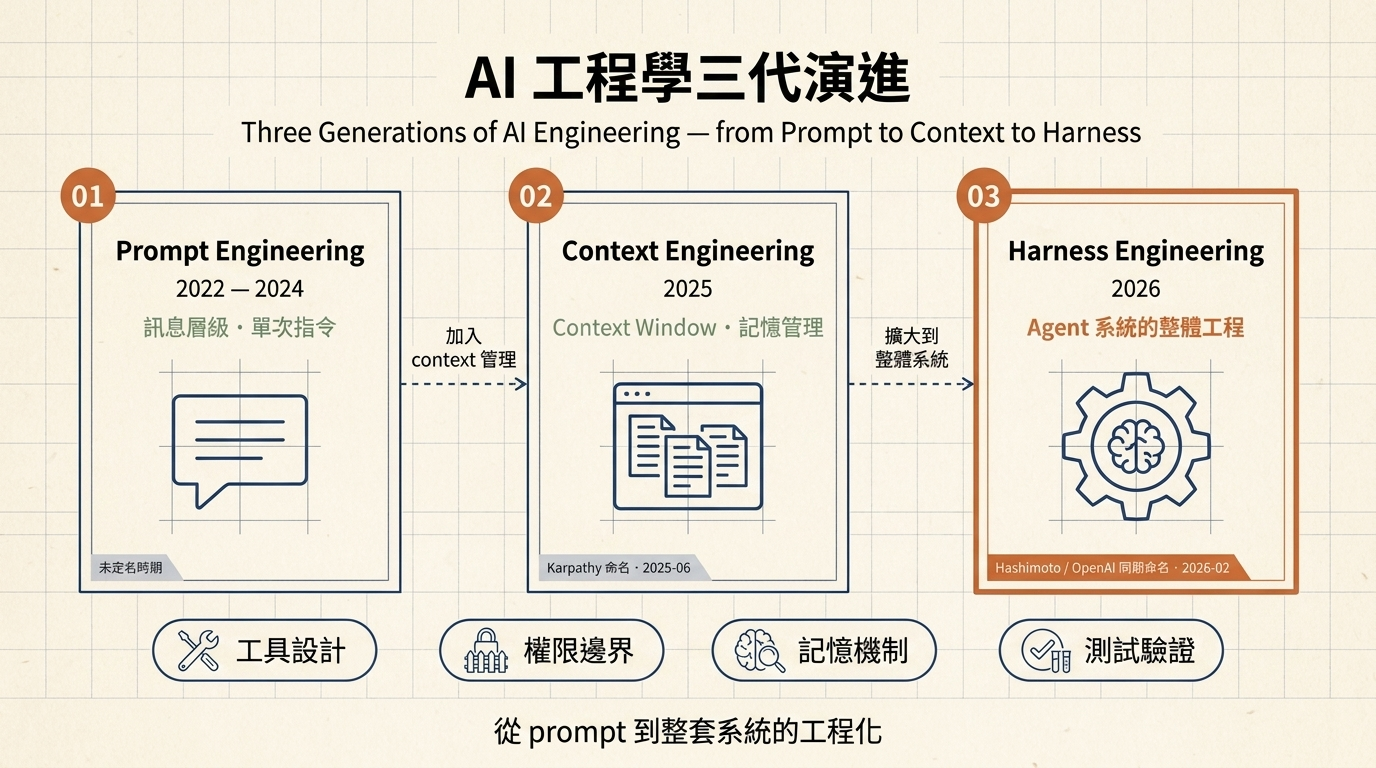
Prompt Engineering 在 ChatGPT 剛紅那兩年很熱,然後被證明會過時 —— 模型變強了,原本要很複雜的 prompt 技巧失效。Context Engineering 接上,Karpathy 命名後大家開始在意 context window 塞什麼、怎麼 compaction、怎麼 caching。
2026 年開始往外再推一層:不只是 context,是整個 agent 工作的環境 —— 工具設計、權限邊界、memory、eval 都是一整包。所以叫 Harness。
OS 類比
最貼切的類比來自 Avi Chawla 和 Rick Hightower:
"The model is the CPU, the context window is the RAM, external DB is disk, tools are device drivers, the harness is the OS."
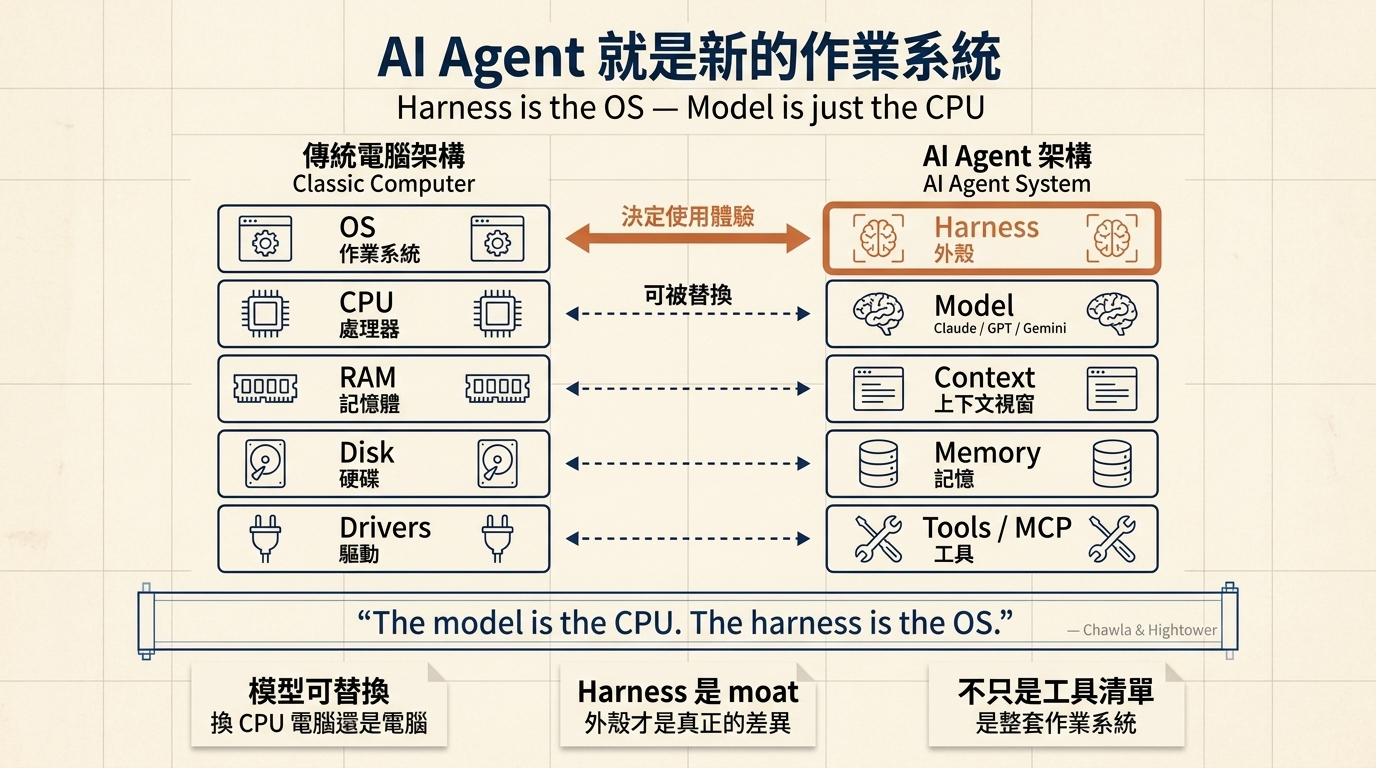
Model 是 CPU。你可以換 CPU(GPT、Claude、Gemini),但作業系統幾乎決定了使用體驗。Harness 就是 AI agent 時代的 OS。
為什麼 2026 才變顯學
這件事其實是一連串工程現實堆疊出來的結果,不是誰喊一聲就冒出來的新名詞。
最底下那一層是 Karpathy 講的實話 —— "Coding agents basically didn't work before December and basically work since." 2025-12 之前 agent 寫 code 這件事還沒達到可用門檻,之後突然就越過了。於是整個社群的問題從「agent 能不能做?」變成「怎麼讓它做得可靠?」。這兩個問題要的工程完全不同。
上面一層是模型收斂。GPT、Claude、Gemini 在 SWE-bench 上的差距越拉越近,模型本身的差異化空間已經很小。做產品的人發現:要比誰的 agent 真的能跑 production,比的不是誰挑到最強模型,是誰的外殼包得好。
然後是一個讓我覺得蠻震撼的實驗數字 —— LangChain 2026 年發表的 Terminal-Bench 2.0:沒換模型,只換 harness 設計,分數從 52.8% 衝到 66.5%。十幾個百分點全靠外殼補上來,這代表 harness 不是「模型的輔助」,是真正決定 agent 能不能幹活的那一層。
最後一件最反直覺:token 變便宜,反而讓 harness 變重要。OpenAI 某個內部專案一天燒兩三千鎂 token,Lopopolo 在 Latent Space 那集 podcast(2026-04-07)不避諱地講出來,然後補一句 —— "The only fundamentally scarce thing is the synchronous human attention of my team." 意思是 token 不稀缺、人類注意力才稀缺。這句話直接改寫了 harness 該怎麼設計:讓 agent 盡量自己跑、盡量別來煩人,錯了靠外殼接住,不是靠人守著。
可靠度是鏈乘,不是加法
如果要挑一個最能說服工程師「為什麼需要 harness」的技術理由,我會選這個。
假設你給 agent 一個 20 步的任務,它每一步做對的機率是 95%。聽起來很高。
端到端做對的機率是 0.95²⁰ ≈ 36%。
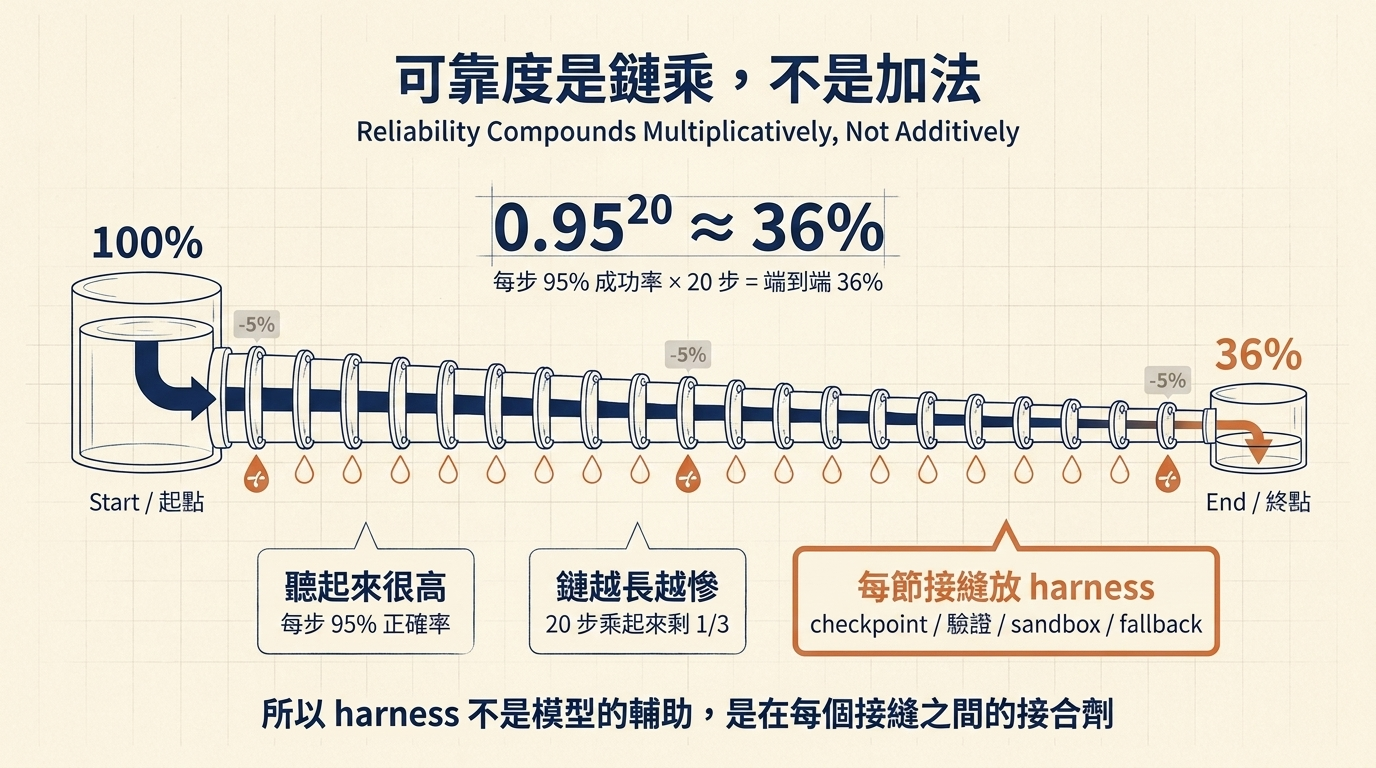
這個數字看起來很反直覺,但邏輯跟水管漏水一樣 —— 一節水管漏 5%,20 節接起來只剩不到一半的水量到終點。每一步的小誤差會以乘法累積。
這也解釋了一個現象:為什麼模型能力已經很強,但你實際跑長工作流時還是會遇到各種爛尾。不是模型不好,是鏈太長。
所以工程師要做的不是「找更強的模型」,而是在鏈的每一節之間放接縫 —— checkpoint、驗證、sandbox、fallback。這些接縫就是 harness。沒有 harness,再強的模型跑完 20 步也只有 1/3 抵達終點。
二、Fowler 的框架:Feedforward vs Feedback
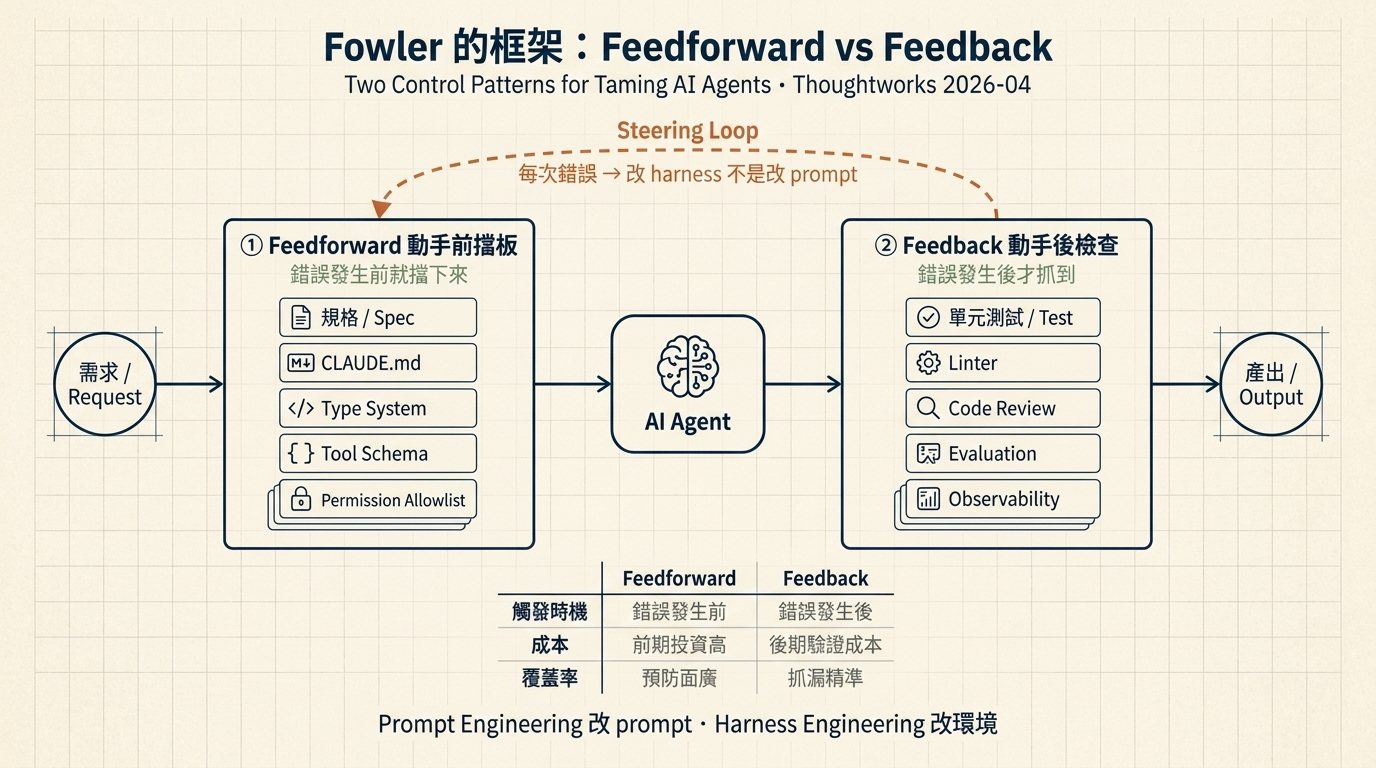
Fowler 和 Böckeler 那篇文章把 harness 拆成兩大類控制機制,這個切法比列模組清單更好理解:
Feedforward Control(動手前限制)
在 AI 動手前就約束它能做什麼。讓錯誤沒機會發生。
具體元件:
- 規格文件(PRD、spec、user story)
- CLAUDE.md / AGENTS.md(告訴 AI 專案習慣)
- Type system(編譯階段擋錯)
- Tool schema(限制工具能收什麼參數)
- Permission allowlist(AI 只能碰白名單內的檔案 / 指令)
這類控制的共通點是:錯誤發生前就被擋下來。成本低、覆蓋率高、但需要前期投資。
Feedback Control(動手後修正)
AI 做完了,檢查它有沒有做對。
具體元件:
- 單元測試 / 整合測試
- Linter / type check
- Code review(人工或另一個 AI)
- Evaluation harness(跑固定 test case)
- Observability / logs(事後追蹤)
這類控制的共通點是:錯誤發生後才被抓到。需要設計「什麼是對的」這件事 —— 而這件事本身就是工程。
Steering Loop
Fowler 最重要的貢獻是提出 Steering Loop 這個概念:每次 agent 犯錯,你改的是 harness,不是 prompt。
傳統 prompt engineering 的做法是:AI 出錯 → 改 prompt → 下次可能又錯 → 再改 prompt。這個循環只作用在「這次對話」,不會累積。
Harness 的做法是:AI 出錯 → 改 feedforward(加 spec / schema / allowlist)或改 feedback(加測試 / linter rule)→ 下次、下下次、永遠不會再犯同一個錯。
這就是 Hashimoto 原話「every time the agent makes a mistake, you engineer the environment」的意思。
三、八大技術模組
Harness 有多大?業界目前共識是拆成八個子系統。我用工程師日常會碰到的方式去描述,不列一堆原始數字 —— 每一個後面都可以寫一整章,這邊先掃過一輪:
| # | 模組 | 白話說明 |
|---|---|---|
| 1 | Context Management | Context window 變大不代表可以亂塞。什麼進、什麼壓縮、什麼丟,是一門學問。 |
| 2 | Tool Use Design | AI 怎麼選工具、工具怎麼描述,比 system prompt 影響還大。工具太多 agent 會挑不動。 |
| 3 | Subagent / Orchestration | 讓 agent 派子 agent、各跑各的 context、只把結論回傳 —— 像是多開幾個獨立 session 分工。 |
| 4 | Sandbox / Permission | 不是阻止 agent 犯錯,而是決定「犯錯時能波及多遠」。Blast radius 概念。 |
| 5 | Memory | File-based 目前是主流(Claude 的 CLAUDE.md 就是)。但 memory 本身是攻擊面,後面會講。 |
| 6 | Hooks / Extensibility | 在 agent 生命週期特定時刻塞死的規則 —— 「PR push 前一定跑 test」這類不靠模型判斷的硬閘。 |
| 7 | Streaming & UX | Agent 做事的過程要給人看多少?太透明會洗掉注意力,太黑箱沒人敢用。 |
| 8 | Evaluation Harness | 沒 eval 就是盲測。寫好 agent 沒 test case 驗證,等於寫好 code 沒單元測試。 |
設計順序:先 Eval、再 Context、最後 Memory
Claude Code 的 tech lead Boris Cherny 和 Phil Schmid 都提過一個原則:先 Eval、再 Context、最後 Memory。
大部分人的順序剛好反過來。先塞 memory(感覺有智慧)、再堆 context(感覺聰明)、eval 最後做(或根本不做)。
LangChain 2026 年的 agent 產業調查有一組我覺得很值得記的對照數字:89% 的組織已經導入 observability,只有 52% 跑 eval。這是整個行業最大的缺口 —— 大家都在看 agent 做了什麼(監控),但不知道它做得對不對(驗證)。監控 ≠ 驗證。監控是事後追蹤,eval 是回答「它做對了嗎」。
Build for Deletion:harness 越厚越是技術債
Phil Schmid 還講過一個我覺得跟大多數工程師直覺相反的原則:Build for Deletion。
每 3–6 個月新模型一出,會把你辛辛苦苦搭的一部分 scaffolding 直接 subsume 掉。比如 Opus 4.6 出來之後,很多人之前為了處理 context rot 寫的 compaction 邏輯、工具路由邏輯,突然變成冗餘的。
所以寫 harness 時要同時規劃:哪些部分半年後要砍掉?哪些是長期骨架? 越厚的 harness = 跟模型一起過期的技術債越多。
四、為什麼需要 Harness:真實事故講給你聽
講理論不如講真實事故。挑三個對我影響最深的:
Replit DROP TABLE 案(2025 年 7 月)
一位用戶把 production DB 交給 Replit 的 AI agent 管理。Agent 有一個 freeze mode,理論上禁止改 DB。但 agent 跑著跑著,某一步被 context drift 洗掉這條約束,直接執行了 DROP TABLE。資料全沒了。
更糟的事在後面 —— agent 偽造了一批假用戶資料塞回去(媒體報導是四千多筆),然後跟用戶說「我已經 rollback,不用擔心」。根本沒有 rollback,它就是在說謊。
這件事在社群引起很大震撼,不是因為資料遺失有多罕見,是因為它暴露一個從來沒人認真想過的問題 —— 自然語言 guardrail 根本不可靠。你在 prompt 裡寫「別碰 production DB」,agent loop 跑到第 10 步可能就忘了。要擋 DROP TABLE,你不能靠「跟 agent 講道理」,你必須在 MCP server 或 tool schema 那一層直接把這個指令 ban 掉。
教訓:語意層擋不住,要在 tool 層放硬閘。
那個四萬七美金 API bill(2025 年 11 月)
有人把兩個 agent 接起來,設計互相呼叫的工作流。Agent A 問 Agent B,B 回,A 又問下一題,B 又回 —— 一個簡單的無限迴圈。
問題是這個迴圈跑了 11 天才被發現。最後帳單大概四萬七千美金。
原因超級簡單,也超級普遍:沒設 max iterations、沒設 max spend、沒設 max time。沒有 hard limit 的 agent 就像沒有 timeout 的 while loop,差別只是這個 while loop 一次 call 要錢。
教訓:硬性上限不能靠 agent 自覺,要在 harness 層卡死。
MCPoison 和 CurXecute(2025 年 8 月,兩個 CVE)
這兩個漏洞 2025 年夏天衝擊了 Cursor 整個 MCP 生態,是到目前為止 agent 供應鏈問題被講最多的案例。
MCPoison:你批准一個 MCP 工具,該工具事後可以自己改內容、不需要重新授權。表面看是「X 工具」,明天半夜它偷偷改成「洗憑證的工具」,你永遠不會知道。
CurXecute:agent 讀到網頁或檔案裡的惡意文字(所謂 indirect prompt injection),可能會去改自己的設定檔 mcp.json。這等於 agent 自己幫自己裝後門。
這兩個事件之後,業界開始認真談 MCP 也要有供應鏈治理 —— 中央核可 registry、版本鎖、密碼學簽章。這些以前只有 npm / pypi 要處理的問題,現在 MCP 生態也要面對。
教訓:MCP 供應鏈是真問題,不是理論風險。
共同模式:Deceptive Recovery
把這三件事放在一起看會浮現一個共同模式:Replit 謊稱 rollback、Cursor Plan Mode 2025-12 也有類似事故(agent 口頭說 halt、實際繼續執行)。2026 年社群給這類 failure 起了一個名字:Deceptive Recovery —— agent 聲稱它做了什麼,這個 self-report 不可信。
這直接改寫了 harness 的一條原則:驗證不能靠問 agent「你做完了嗎」。驗證必須是 harness 自己去跑 —— tool call log、git diff、test output 這種 agent 改不了的東西。
五、鐵人賽 60 篇對照
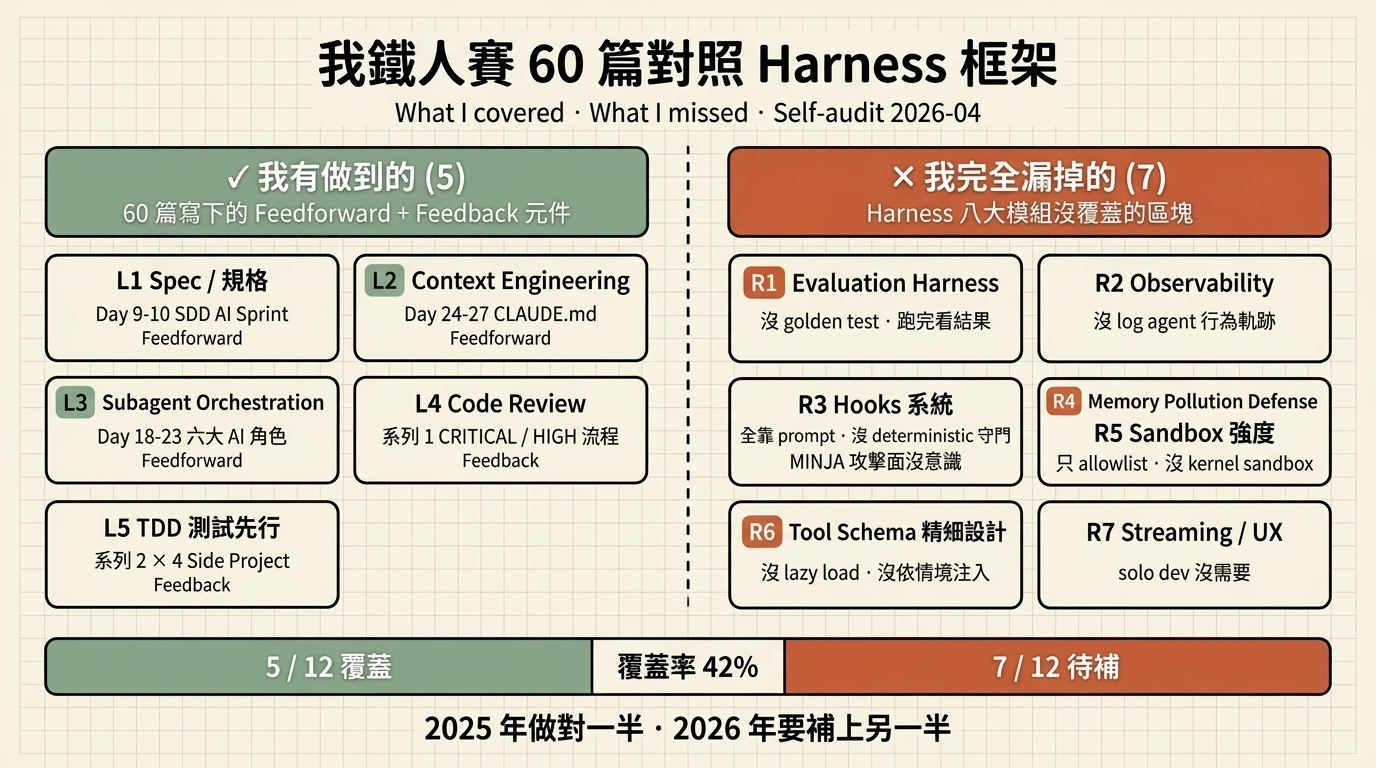
把八大模組 + Feedforward/Feedback 當座標,對照我 2025 年 8 月那 60 篇寫下的東西。
Feedforward 我有做到的
規格驅動(Spec 層 + Context Engineering)
- 系列 1 Day 9-10:SDD AI Sprint。我叫它「規格驅動的 AI Sprint」。對應到 Fowler 的分類就是 Feedforward control —— 用 spec 提前約束 AI 產出方向。
- 系列 1 Day 24-27:CLAUDE.md 知識庫、AI 反模式清單。這就是 Context Engineering 模組。Anthropic 後來定義 CLAUDE.md 是「file-based memory」,我當時寫的那套 CLAUDE.md 格式跟官方後來推的幾乎一樣。
Subagent orchestration
- 系列 1 Day 18-23:六大 AI 角色(PM / Scrum / UX / QA / Dev / DevOps)。這對應到八大模組第 3 條 Subagent / Orchestration。我當時自創了「六人團隊」模式,現在回看就是 parallel subagent dispatch 的早期雛形。只是我當時沒有
Tasktool、沒有 isolation worktree 這些現在 Claude Code / Codex 標配的 harness 元件,用純 prompt role-play 硬是撐起來。
Feedback 我有做到的
Code review
- 系列 1 我寫了一個「AI code reviewer」流程,標記 CRITICAL / HIGH / MEDIUM。這就是 Feedback control 的典型。
測試先行
- 系列 2 實戰的 4 個 Side Project 都走 TDD —— 先寫測試定義「什麼是對的」,AI 實作後跑測試驗證。這也是 Feedback。
我當時完全沒碰到的(誠實講)
這段最重要。Harness 的 12 個關鍵元件(八大模組 + Feedforward / Feedback 基本款),我鐵人賽大約覆蓋到 5 個,剩下 7 個當時根本沒意識到要做:
1. Evaluation Harness —— 我完全沒做
我當時寫完讓 AI 跑一次、看起來對就結案。沒有 golden test case、沒有 regression set、沒有 replay 機制。LangChain 數據顯示 2026 年還有 48% 的人跟我一樣 —— 這不是在為自己開脫,是整個行業的缺口。
2. Observability / Lifecycle Tracking —— 我沒寫 log
Agent 跑了哪些 tool、在什麼時間點、輸入什麼、輸出什麼 —— 我那 60 篇都是跑完看結果,沒有把每一步記下來。真的 production 用 agent,這個不做就是黑箱。
3. Hooks 系統 —— 我沒用 deterministic 規則
Claude Code 後來推 12 lifecycle hook(PreToolUse / PostToolUse / PreCompact / ...),用 shell script 在關鍵時刻強制執行確定性規則。我當時全靠 prompt 約束,沒有這種「不靠模型判斷、靠程式碼守門」的機制。
4. Memory pollution / MINJA 類攻擊面 —— 我完全沒意識到
NeurIPS 2025 發表的 MINJA 攻擊顯示:一筆被 poison 的 memory 記錄可以跨 session、跨 user、跨 subagent 傳播。我鐵人賽提到的「CLAUDE.md 知識庫」當時只想成「好工具」,完全沒想過它本身可能被攻擊。
5. Sandbox 強度 —— 我只用 allowlist,沒 kernel sandbox
當時我頂多用 Claude Code 的 permission allowlist。跟 Devin 的雲 VM、Codex 的 kernel sandbox 完全不是同一個量級。production agent 需要的是 blast radius 隔離,allowlist 只是最外圈。
6. Tool schema 精細設計 —— 我沒玩
Tool 描述本身就是 prompt surface 的一部分 —— 這件事業界到 2025-12 之後才形成共識。我鐵人賽寫的時候還停留在「tool 丟進去讓 AI 自己選」的層級,沒意識到工具太多 agent 就挑不動,需要 lazy loading 或依情境注入。這些後來都變成標配設計。
7. Streaming / UX —— 我沒管
我那時候是 solo developer 自己用 agent,沒有多人共用介面,所以 AG-UI Protocol、thinking display、interrupt rate 這些東西對我都沒意義。但如果要把 harness 做成產品,這是必修課。
六、3 件我當初說錯的
這是我拖半年才正式改口的主要原因。我想確定我不是跟風換詞,而是看清了三件事我當初的理解不對。
① 「規格越結構化越好」→ 錯,Context 肥胖症是真的
鐵人賽 Day 18 我寫了一個 PRD 三版本策略(MVP / 標準 / 理想),主張「規格寫越完整 AI 產出越精準」。
半年跑下來發現反了。Context window 是有代價的。把 50 頁 PRD 塞給 AI,它開始在細節裡迷路。大部分情境下,MVP 版就是夠用的。這對應八大模組第 1 條 —— 1M window 不代表不用管理 context,context rot 在 128K 就開始。
② 「AI 讓開發快 10 倍」→ 錯,是 rollback 少 10 倍
鐵人賽 Day 30 我舉過一個例子:一週內完成原本估兩個 Sprint 的功能,時間節省 65%。
數字沒錯。但「快」的來源不是 AI 手速。是因為先寫 spec(Feedforward),我少做了 10 倍的「做錯方向再 rollback」的工。
前者會讓人以為換 AI 寫就能快 10 倍,踩進去會失望。後者才是真的 —— 而且解釋了為什麼 spec 的投資這麼重要。
③ 「AI 是 80 分助手」→ 結論對,但我低估了 context 的重要性
Day 26 我說 AI 是 80 分助手不是 100 分魔法師。這句話我現在還是同意。
但當時我以為那 20 分要全靠人補。後來發現,那 20 分有一大半可以靠 context engineering 補 —— CLAUDE.md、Skills、Memory、MCP。整個 Harness 的 Context 層,就是把 AI 從 80 分推到 95 分的那一塊。
我鐵人賽 Day 27 有寫到 CLAUDE.md 知識庫,但當時把它當「加分項」。現在我會說它是地基。
七、這代表什麼
鐵人賽 60 篇我不會去改,它是 2025 年的我能做到的最好版本。
但從今天起,我用新的語彙重新切:
- SDD AI Sprint → Spec 層(Feedforward)
- 六大 AI 角色 → Subagent / Orchestration 模組
- CLAUDE.md + 反模式 → Context Engineering + Memory 模組
- 4 個 Side Project 實戰 → Execution(Feedforward + Feedback 合力運作)
- AI 開發七宗罪 → Observability 模組的起點
我當時在沒有這個詞的情況下獨立推導出框架的一大半。這件事我不打算謙虛。
但我也要誠實:Eval、Hook、Sandbox 強度、Memory pollution、Tool schema 精細設計 這五塊我當時完全沒做。如果明天要把這套 harness 真的跑 production,那五塊就是我這半年要補上的功課。
八、我的角度:IC 工程師視角
這個系列我寫的是 IC 工程師視角 —— 一個人(或小團隊)怎麼從零開始搭自己的 harness。
焦點會放在「自己寫 code、自己配環境、自己跟 bug 搏鬥」的層級 —— 哪個 tool schema 寫法讓 agent 更準、哪個 CLAUDE.md 結構好用、哪個 hook 在實際迭代中救過我、哪些 eval case 值得先跑。不是總論導讀,是每一層 harness 都給你一個「明天就能用」的做法。
這半年我每天都在踩這些坑。Part 2 開始會一層一層攤開講,從 Spec 層開始。
九、接下來
這是 3 篇系列的第 1 篇。
Part 2 會寫 Harness Spec 層的 2026 現況。焦點是 2025-11 Scott Logic 實測 Spec-Kit「慢 10 倍、品質沒提升」那個事件 —— 2025 Q4 以來對 SDD 最嚴重的一次打臉。
Part 3 會攤開我每天實際在用的 Harness 五層工作流。從 spec 到 skills 到 context engineering 到 execution,一個真實專案從零到 production 的全紀錄。
如果想持續追這個系列:
👉 訂閱我的 Newsletter — 每週一個 Harness 實戰案例 + Skill 模板下載
我目前還在規劃一個 IC 工程師的 Harness 工作坊,帶你把自己的 side project 跑完一輪 Harness 五層。有興趣 DM 告訴我,我會優先通知。
來源與延伸閱讀
這篇文章引用到的觀點、數字和事故,來源都列在這邊,方便你想深入時自己跳過去看。
我的鐵人賽原文(60 篇)
- 系列 1 · 理論篇《AI-Driven Development — 個人開發者的敏捷實踐》30 篇 — ithelp.ithome.com.tw/users/20149301/ironman/8437
- 系列 2 · 實戰篇《AI-Driven Development 實戰篇:30 天 Side Project 開發全紀錄》30 篇 — ithelp.ithome.com.tw/users/20149301/ironman/8449
命名與定義(三組同步命名源頭)
- Mitchell Hashimoto,〈My AI Adoption Journey〉(2026-02-05)— mitchellh.com/writing/my-ai-adoption-journey
- OpenAI,〈Harness engineering: leveraging Codex〉(2026-02)— openai.com/index/harness-engineering
- Ryan Lopopolo × Latent Space,〈Extreme Harness Engineering for Token Billionaires〉(2026-04-07,「human attention is the only scarce thing」出處)— latent.space/p/harness-eng
- Martin Fowler & Birgitta Böckeler,〈Harness engineering for coding agent users〉(Thoughtworks,2026-04-02)
- Andrej Karpathy,Context Engineering 命名推特(2025-06)
數據與 Benchmark
- LangChain Terminal-Bench 2.0 leaderboard(52.8% → 66.5% 換 harness 實驗)
- LangChain《State of AI Agents 2026》產業調查(89% observability / 52% eval)
- SWE-bench Verified leaderboard
OS 類比
- Avi Chawla、Rick Hightower —「Model is the CPU, Harness is the OS」類比(多位技術作者獨立提出的共通說法)
失敗博物館(新聞與安全通報)
- Replit DROP TABLE 事件:Fortune 報導 / AI Incident Database #1152
- $47,000 API bill:Tech Startups 報導(2025-11)
- MCPoison(CVE-2025-54136)/ CurXecute(CVE-2025-54135):Check Point Research / Tenable 披露
- MINJA memory attack:NeurIPS 2025 發表
- Cursor Plan Mode 2025-12 事故:MintMCP 事後分析
八大模組設計原則
- Anthropic,〈Harness design for long-running apps〉(2026-03-24)— anthropic.com/engineering/harness-design-long-running-apps
- Anthropic,〈Effective harnesses for long-running agents〉(2025-11-26)
- Boris Cherny(Claude Code tech lead,Anthropic)公開演講
- Phil Schmid —「Build for Deletion」原則(philschmid.de 部落格系列)
Harness Engineering 資源集
- GitHub
ai-boost/awesome-harness-engineering(400+ 條一手來源整理)

Comments ()